


Broadly data systems can be grouped into two categories
- Systems of Record : Act as source of truth. In case of conflict, data in this system is considered as correct.
- Derived System: Derived from Systems of record and generally modeled based on consumers. Cache is an example of derived system
In this article, we will look at batch processing to feed a derived system from source systems.
Basic implementation of a batch processing system is a shell script written in unix.
cat /var/log/nginx/access.log |
awk '{print $7}' |
sort |
uniq -c |
sort -r -n |
head -n 5
The above script reads the nginx log and gives the top 5 visited websites. A system(top 5 websites) derived from the nginx logs(source).
Each command in unix does only 1 job and they can be chained together in the sense of pipe and filter architecture. The key points of unix philosophy relevant to data processing are
- No assumptions on the previous and next steps except for a standard interface (I/O)
- Data is not mutated i.e. each step produces a fresh copy i.e. can be rerun multiple times without issues
- Easily debuggable as any step can be the last one and piped to a file
This core philosophy is amazing but limited to single machine. This is where Hadoop comes in.
Hadoop
Hadoop extends the unix philosophy across thousands of machines. The programming paradigm of Hadoop is mapreduce. Mapreduce is like a unix job which takes one or more inputs to produce outputs. Instead of unix filesystem, Mapreduce reads and writes to Hadoop Distributed File System.
HDFS is spread across the entire cluster of machines but gives the perspective of a single filesystem to mapreduce. HDFS is engineered for fault tolerance by replicating data across different machines in the cluster. HDFS contains a daemon running on each machine in the cluster which allows other nodes to access files in the machine. A central node keeps track of the location of all file blocks. This central machine is called Namenode. In earlier versions, namenode acted as the single point of failure.Later versions had namenode in High availability mode.
MapReduce can parallelize a computation across many machines. This helps the programmer to not worry about handling parallelism. At its core, mapreduce contains of two parts - mapper and reducer. They are callbacks with each one handling a different type of work. Generally written in languages like Java,python but certain databases like MongoDB and Couch use javascript.
A mapper takes each record as input from HDFS and generates Key Value pairs as output. Before this step one of the fundamental magic happens. Generally, we read data from a database and this is processed in a server. In Hadoop, mapper code is actually transferred to the node containing the data blocks. This is because the amount of data to be read will be more in case of big data applications. The number of map tasks is determined by the number of data blocks the application is processing.
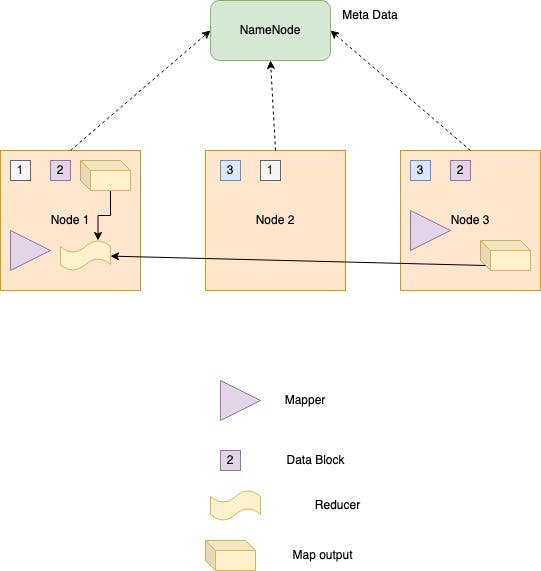
Each mapper writes its output to local storage. But here the framework does the extra work of sorting the output based on keys. Once mapper finishes the output, it notifies the reducers to start processing. The number of reducers is configurable. In the above image, number of mappers is 2 as it is reading data blocks from node 1 and node 3. Reducer is configured to be 1 so the output of mapper in node3 is transferred to reducer in node1. This process of shuffling the data across nodes is time consuming. The number of reducers generally leads to the number of output partitions.
Reducer can write the output to HDFS or to other systems. As in Unix, mutliple mapreduce jobs are chained together to create complex workflows.This simple paradigm enabled solving lot of big data problems. But this was not without its downsides. Implementing a complex processing job using the raw MapReduce APIs is actually quite hard and laborious. This led to development of higher-level programming models (Pig, Hive, Cascading, Crunch) on top of MapReduce.
Dataflow dethroned mapreduce as the de facto paradigm of big data thanks to its impressive performance. The fundamental concept is dataflow handles entire workflow as one job, rather than breaking it up into independent subjobs. There are no strict mappers and reducers but flexible functions called as operators. They are chained together as needed and each operator passes its output to another operator. This offers several advantages over mapreduce paradigm
- Sorting can be done on needed basis. In mapreduce, mappers always sort.
- No strict mappers or reducers and logic can be written as needed in operator.
- Since entire workflow is known to scheduler, it can do lot of local optimizations.
- Intermediate output(eg:mapper output) can be stored in memory for faster access instead of disk. We can recompute state as it is derived data.
Tez was one of the dataflow execution engines which sped the existing programming models like Pig or Hive. Spark and Flink are alternative computing frameworks which process data much faster.
The distinguishing feature of a batch processing job is that it reads some input data and produces some output data, without modifying the input. The input data is bounded i.e. size of the data is known. In the next post we will look at streaming which handles unbounded data.