


In previous post we discussed about batch processing. The key assumption in batch processing is that data has a defined start and end. In reality there is no end as data keeps on flowing. Batch works by defining artificial boundaries - end of day, week or month etc.
Producers emit events based on certain conditions in streaming paradigm. Consumers react based on these events. Streaming paradigm relies on a messaging infrastructure to decouple producers and consumers.
Consider a simple example of order processing system.
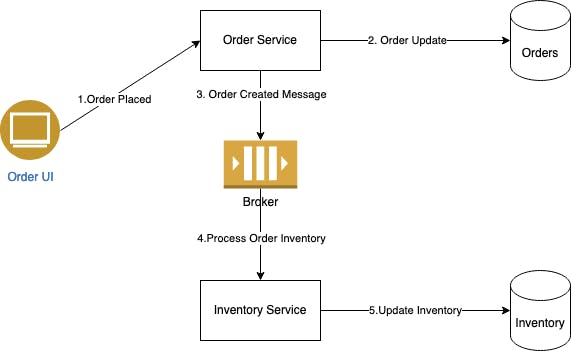
Order gets placed and Inventory service should update the inventory based on the order.
Direct Messaging
Many messaging systems use direct network communication between producers and consumers. Examples are
- UDP Multicast : Producer sends events to many consumers via UDP protocol. Producers must maintain history of messages in case of reprocessing.
- Brokerless messaging libraries (ZeroMQ,nanomsg) do the same but over TCP or IP multicast.
- Producers making HTTP call to all interested consumers to publish the event
High throughput is achievable in these cases. Applications should be online always to achieve reliability.
Message brokers
Alternative is to use message brokers as illustrated in the Order Processing example. Message broker is database for message streams with some differences. Message brokers increase processing time due to asynchronous communication.
Two main communication patterns exists in message brokers
Load Balancing: Each message is delivered to one of the consumers. This ensures that consumers can parallely work on the queue.
Fan out: Each message is delivered to all consumers. In our order application, fan out would be ideal as each consumer would need the order placed message.
There are subtle issues in distributed processing of messages from the queues. The processing order of messages cannot be guaranteed always. In traditional message processing, broker deletes messages once they are processed by consumer. A new consumer can process only from the available messages. This led to creation of log based message brokers
Log Based Message Brokers
Log based message brokers are like log structured storage. Producers append messages / events to the log. Consumers read the log sequentially from start to end. To increase throughput, log is divided into multiple partitions. Each partition is hosted on a different machine and is analogous to a log.
Within each partition, broker assigns a monotonically increasing number for message called offset. Consumers periodically scan the log for new messages. Consumers maintain the previous read point aka offset. This helps to read only the new messages from the last read point. Apache Kafka is an example of log based message broker.
Lets imagine scenarios for our order processing system and explore the desirable effects
| Scenario | Direct connection | Message brokers | Log based Message brokers |
| What if the order volume is high beyond the speed of Inventory service? | Drop messages. Not desirable. Apply back pressure i.e. regulate producer to send messages | Can buffer messages if polling Inventory service is overwhelmed if push based | Desired as inventory service reads in its own pace |
| What happens if nodes crash ? | Lost messages | Reliable storage | Reliability and available even for new consumers later |
Let's extend the order processing example. We will introduce an analytic function to report on number of orders processed daily. This is done with the help of an analytical store such as data lake or data warehouse. Should we build another pipeline to produce the event?
Change Data capture
Would it not be great if we can use orders database as the source of truth? Each database maintains an internal representation of its update log. External systems also can process the long in case of CDC. Typical setup is to expose the database logs into a log based message broker. Consumers consume the data from the broker. This ensures database as the leader and single source of truth. The main idea here is that data updates are sent as a Stream of events which are further processed by consumers continuously.
Event Sourcing
Domain Driven design discussed this technique in detail. Application is modeled as a series of events or facts based on user action. The events are stored as immutable log to construct the latest state. There are specialized event stores but log brokers also can be used. Database contains the latest snapshot but log brokers can recreate state if needed. Event sourcing differentiates between command and event. User placing the order is command. Once the order is accepted it becomes an event. A desirable side effect of this approach is that written structure of data can be different from query pattern.
Stream processing
We have discussed so far about sources generating a stream of events. There are three next steps
- consume the data in event and create a replica or cache
- consume the event and notify user via mail or alert
- consume the stream and produce another stream
The third step is the land of stream processing which we will explore further.
Complex Event Processing
In a nutshell, CEP is about filtering events matching a pattern.it is analogous to regular expressions but it is done on a stream instead of string. CEP systems process the stream and generates an complex event with the pattern
Stream Analytics
Stream analytics is all about aggregating the data over a window. For example, number of orders processed in the last 8 minutes.
Windows
Window defines the period of time over which processing is carried out. We will look at few window types
| Window Type | Duration | Window1 | Window2 |
| tumbling | 1 minute | 9:00:00 - 9:00:59 | 9:01:00 - 9:01:59 |
| Hopping | 5 minute with I minute tumble | 9:00:00 - 9:04:59 | 9:04:00 - 9:07.59 |
| Sliding | 5 minute | 9:00:00 - 9:04:59 | 9:00:01 - 9:05:00 |
| Session | No duration fixed for session |
Stream joins
In this section, we will look at joining datasets in stream processing.
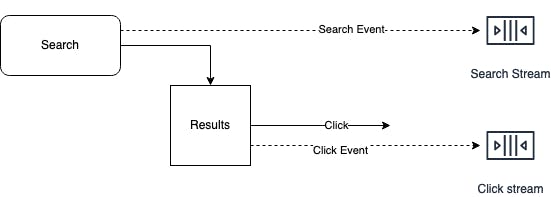
- Website has a search feature and each search is logged as an event.
- Results are displayed on the website and click on the result triggers another event.
Stream-Stream join
If we need to calculate the click through rate of search terms, we need to join both the stream of events. This is stream to stream join. Every search is not clicked so the stream processor has to maintain the search events for a specified period of window called state.
For example, all the events that occurred in the last hour are indexed by session ID. When search event occurs, it checks the click event stream for the same sessionid and does the join.
Stream-Table join
Now imagine in the above example, we also need to display the person name who clicked the search results. We can join the stream with user profile data which can be consumed as a static table. This scenario is stream to table join.
Fault tolerance
Since streams are unbound, the issue of fault tolerance is more difficult in stream processing. But there are some options to ensure fault tolerance.
Micro batching: Here stream is divided into small blocks(window of 30 seconds etc.) and treat each block as a batch.
Checkpointing: Stream processor periodically generates rolling checkpoints of state and writes to durable storage.
In this post, we have looked at event streams and message brokers. We looked finally at processing these event streams to generate business outcomes.