


This covers the fundamental aspects of a data store - Storage and Retrieval
We will start with understanding the data structures used commonly in the database. First is log - What ?
This is not the application logs. This refers to the concept of append only structures. For example consider a simple key value store for storing product and quantity. We store such as below in text file
Apple:10
Mango:5
Somebody buys an apple from us. Rather than updating we can append a record
Apple:10
Mango:5
Apple:9
What we get ? Good performance during insertion but suffer during retrieval. To get the current quantity of Apple, we need to iterate the file and find the last record. Append only logs provide the best performance for heavy write workloads
What is the use of storing if we cannot see the value ? Not just that, can I see it quick enough so that my customer does not get tired of waiting.
Here comes indexes.
An index is an additional structure that is derived from the primary data.
Indexes must be structured to improve read performance but will affect write performance. Hence, it is a trade-off which must be carefully chosen.
We will see few indexes widely employed
Hash Index
Considering our fruit shop above, we introduce an additional step. After writing to the file, update the key and the byte offset in an in-memory Hashmap. While retrieving, we can directly go the byte offset and read the data. In our example, value is a simple string but it can be arbitrarily long JSON in reality.
Since we are always appending, what if we run out of disk size?
A good solution is to break the log into segments of a certain size by closing a segment file when it reaches a certain size, and making subsequent writes to a new segment file. This is where compaction kicks in. Compaction is a background process which will identify the duplicate records and write out into a new file before deleting the old files.
Though append only log provides nice benefits for concurrency and crash control, it has serious limitations
- Hash keys must fit in memory. If spilled to disk performance drops
- Range queries are inefficient. Find products starting with A1 to A100 (scan all the keys)
SSTables
Let's address the memory and range queries issue. Instead of storing the segments in random order, what if we store the keys in sorted order. Ahem
Sorting on disk is not easy. OK, let's store sorted keys in memtable (in-memory balanced tree RBT). Let's look at the sequence of operations to maintain a structure
- Whenever a new write happens, Store it in memtable
- When a threshold is reached(based on machine RAM), flush it out to SSTable (Sorted Structure Table) file on disk.
- During the flush process, store the data in a new memtable.
- Once the flush process is complete, delete the old memtable
- To serve a read, first look in memtable then fallback to recent SSTable file and so on
- Run compaction periodically
This addresses the problem of range queries. This also means we need not store all hash keys and offsets in memory. It is fine to store Apple and Cucumber offsets in our friendly in-memory hashmap from hash index section. We know Banana will be in between these two as keys are stored in sorted order.
LSM-Trees
The above SSTable methodology works well. But what if the machine suddenly crashes ? We can build in memory hashmap from SSTable file. But our memtable with recent writes is gone...
We revert to append only logs. The sole purpose of this file is to restore to memtable after crash. It will be deleted as soon as memtable is written to disk. Hence, it is termed as Log Structured Merge.
B-Tree index
The most widely used is neither LSM nor Hash indexing. It is B-Tree index which is one of the oldest. It follows an entirely different approach of updating in place
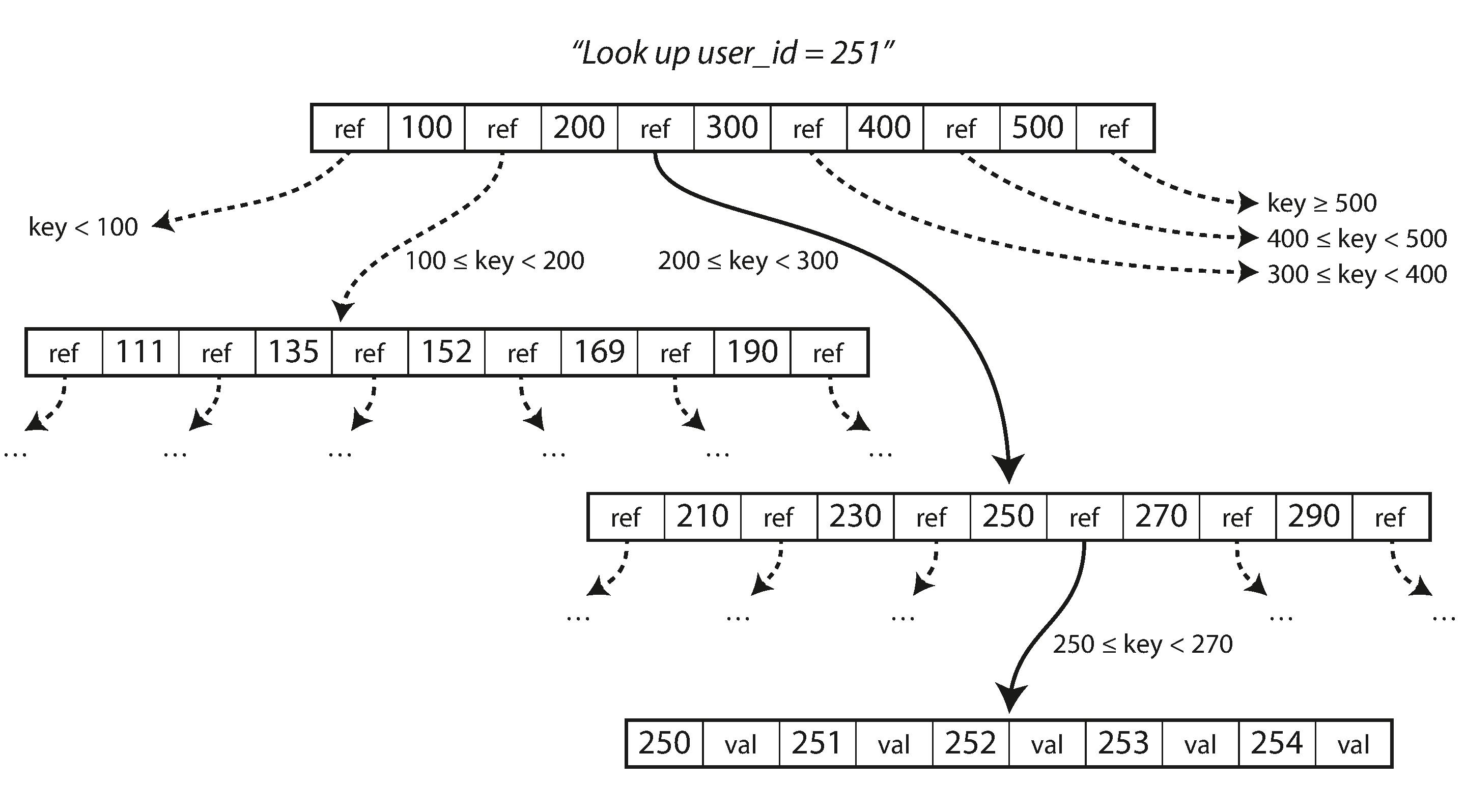
Image Credits: Designing Data Intensive Applications
As indicated in the image above, a B-Tree of pages is constructed and top level hold references to the pages while the leaf level nodes contain the page along with value. A write involves finding the page and updating the value. To ensure reliability of the database before writing to B-Tree, update is written to a Write Ahead Log (WAL). This is an append only log but only used to restore the B-Tree in case of an crash. Also B-Trees uses lock to guarantee concurrent update of values.
As a rule of thumb, LSM-trees are typically faster for writes, whereas B-trees are thought to be faster for reads. LSM trees occupy less space on disk due to the compaction process it runs frequently. But this compaction process itself can be a major factor limiting read/write performance. Strong transaction guarantees can be easily supported in B-Tree due to its existing locking mechanism.