


This chapter deals with data encoding to handle evolution of software systems. There are two different representations supported by programs
- Memory : Data formats performant for CPU access
- Network: Format suitable for distributed processing
Data is sent across different systems. In a trivial system, from database to application and application to frontend. So we need translation between memory format to network format. This translation is called encoding and the reverse is decoding
We will look at the various encoding formats and their capabilities
Language Specific
- They are very convenient and less code compared to others
- But cannot mix and match languages
- Security is a concern as arbitrary byte sequences can be encoded into class structures
- Versioning changes are not included in most
- Efficiency/Performance is not at the forefront
Textual
- Includes JSON, XML and CSV
- Popular and human-readable
- Optional schema support
- No strict type understanding in CSV
- Binary data needs to be base encoded
- Best format across organizations
Binary
- More compact
- Faster to parse
- Works well within a controlled environment like Business unit or organization
We will look at few of the binary encoding formats with the following JSON as example
{
"userName": "Martin",
"favoriteNumber": 1337,
"interests": ["daydreaming", "hacking"]
}
Message Pack
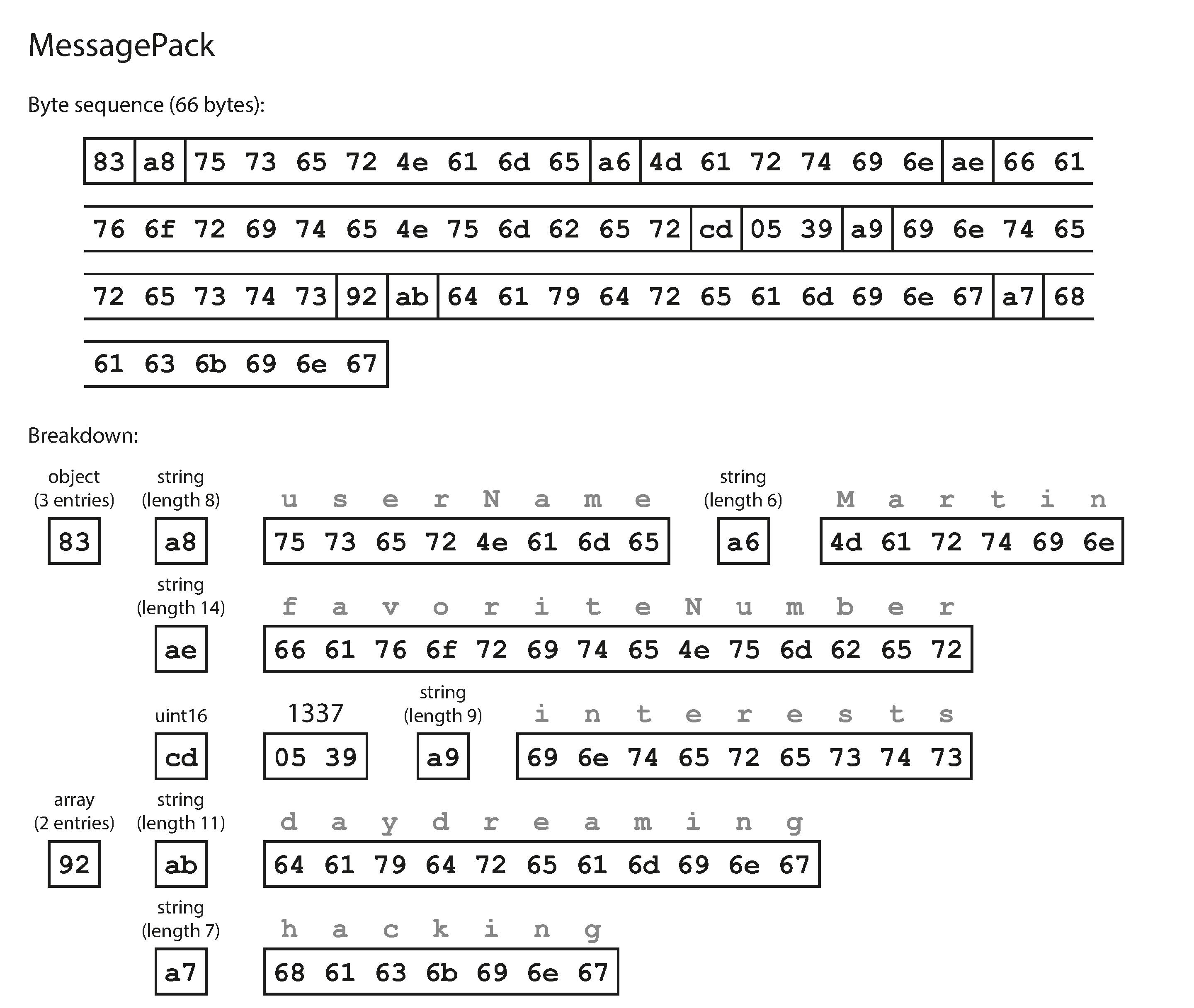
- 0x83 = 80 indicates object with 3 for 3 fields Similarly, each field type and corresponding value in ASCII is represented
Protocol Buffer & Thrift
Both require a schema for encoding the data. The book discusses the schema and code generation with schema in detail. These formats use tags instead of field names. For example, tag 1 represents username. This gives the following benefits
- We can change field names
- We can add additional fields by using tags
- Lesser size than sending field name
A difference between protocol buffer and Thrift is that it does not support array datatype. It uses a repeated marker to handle a list of elements. This in turn provides the advantage of making an element optional. This provides the capability to change an optional (single-valued) field into a repeated (multivalued) field.
Avro
Avro provides a greater support for schema evolution by supporting two schemas - Writer and reader schema. In all previous formats, both should be the same. In Avro it is enough if they are compatible. Avro translates from writer schema to reader schema at runtime.
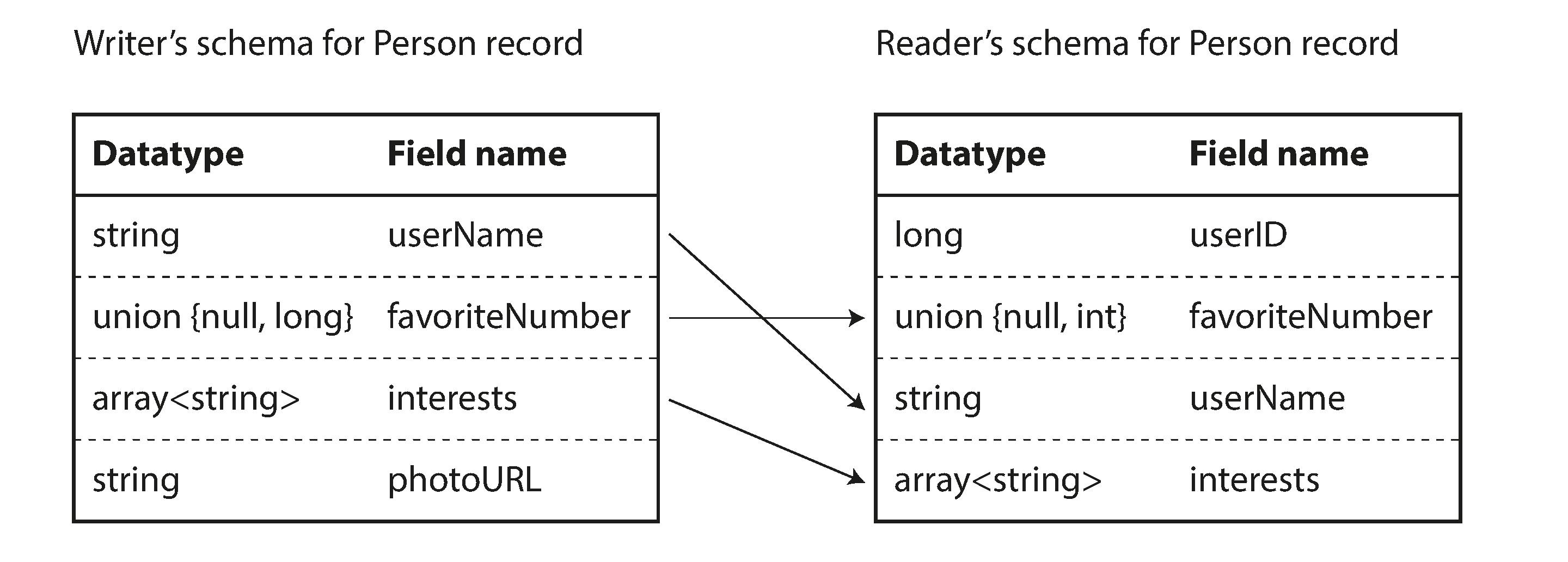
Data flow Types
In the final section, the common data flows in today's applications are discussed
- Dataflow through Databases
- Espresso uses Avro for schema evolution
- Many DBs allow only addition of columns
- Dataflow through Services
- Thrift, Avro and gRPC are used
- Message Passing
- Message brokers and actor frameworks