



Why we distribute data across multiple machines ?
- Scalability (Exceeds single machine capacity)
- Increase availability(Fault tolerance)
- Reduce Latency(user proximity to data)
Replication caters to point 2 and 3 as it is about keeping copy of same data across nodes. Data partitioning handles point 1.
One of the common ways to handle replication is the leader-follower pattern. One node acts as the leader, and all writes are addressed to the leader. Followers synchronize with the leader, synchronously or asynchronously. Follower nodes increase read throughput.
The following are fundamental problems in replication(distributed systems*)
- Node failure & subsequent leader election
- Unreliable networks
- Tradeoffs relating to
- Consistency
- Durability
- Availability
- Latency
We will look at the replication methods used for leader-follower replication
Statement Based Replication
Leader sends each DML statement it receives to all followers. The statement is executed on all followers. This presents the following failure scenarios
- Non-deterministic operations, such as Now(current time). Different nodes will have different value
- Statements need to follow exact ordering to handle auto increment columns. Difficult to handle in case of concurrent transactions
- Side effects of statements(triggers, stored procedures, user-defined functions) should be deterministic
Write Ahead Log(WAL) shipping
This involves shipping the leader WAL to all followers. The main problem with this approach is that leader and followers should be on the same version. Potential version mismatches can cause conflicts.
Logical Log(Row based) Replication
This is similar to the previous approach. Here, instead of internal format, a logical log is sent across for DML operations. Hence, it can be used even by external applications. This can be auto triggered by CDC solutions which are widely in place today.
Leader based replication is great for read-heavy workloads. Since replication is asynchronous, followers will have replication lag sometimes. If synchronous replication, write performance suffers. We will discuss a few concerns related to replication lag.
Read your write
User should see the updates they are making. This can be handled by reading user updates from the leader. Other users' updates will be read from follower. This breaks down if the application is write-heavy. Another is coordinating based on write timestamp. Fetch data from nodes which have data greater than user's last update timestamp. This is very tricky to coordinate across many devices.
Monotonic Read
Suppose user A makes an update on t1 from 2 to 3. This update propagates to node1 but not to node 2. Now, if User B reads, they see the value of 3(Node 1). After refresh, they see value 2(Node 2). This is confusing as the user sees an old value. This can be handled by redirecting the user always to the same replica.
Consistent Prefix Reads
The other case is a variation of the above. User sees the value 3 first and then value 2. This is in a different order than writes. Consistent Prefix Reads ensure that reads happen in the same order as writes.
Distributed transactions are hard and eventual consistency leads to above failure modes
Author next discusses multi leader replication. This is essential for high availability of leader and also scaling write traffic. The biggest challenge in multi leader replication is handling write conflicts.
- Last write wins - Give each write a unique ID and pick the write with the highest ID. This works well in single node cases, but with many nodes and unreliable clocks this breaks down
- Allow the application to handle the conflict. Error-prone and difficult to handle
- Conflict-free replicated data types allows concurrent editing and auto resolves the conflicts
- Mergeable persistent data structures like git does three-way merging
- Operational Transformation Algorithms designed for collaborative editors can handle conflicts
Next, we will look at few multi leader topologies
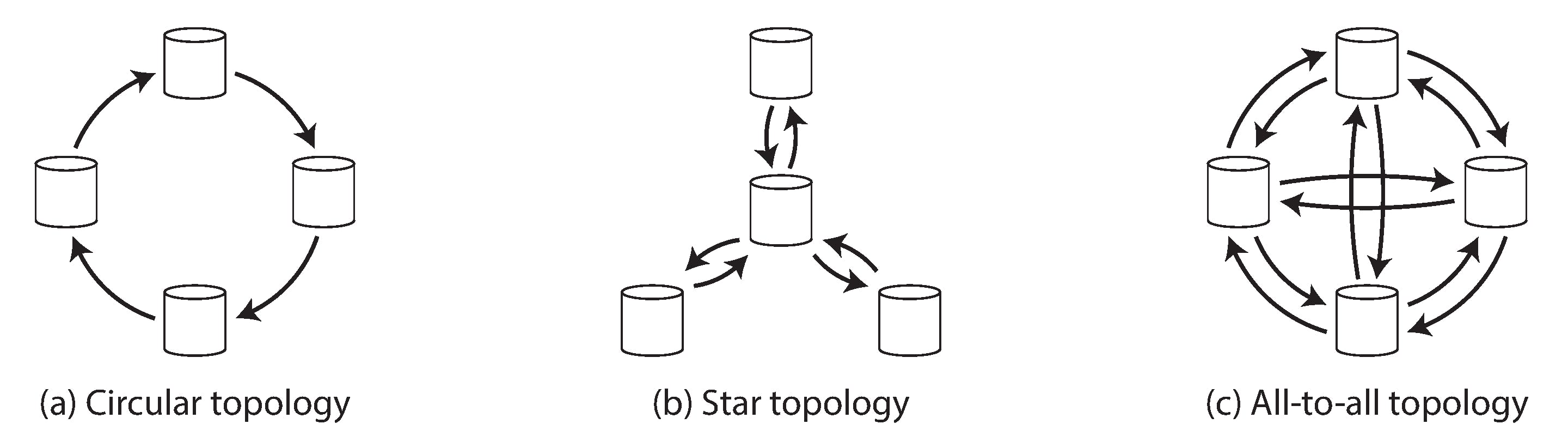
a) Each node passes data to the next node. If one node fails, there is data loss b) Similar single point of failure c) Avoids SPOF, but some network links may be slow leading to monotonic reads problem.
Leaderless replication is another replication strategy pioneered by DynamoDB. Since any node can serve data, what happens if a node is down and comes online later ?
In these types of databases, requests are not served by a node but many nodes. Version numbers detect the most up to date write. The version number approach fails when there are many replicas accepting writes concurrently.
Instead, we need to use a version number per replica as well as per key. Each replica increments its own version number during a write. It also keeps track of the version numbers from each of the other replicas. The collection of version numbers from all the replicas is called a version vector.
Stale node catches up to other nodes, either by
- Read repair: Read data from many nodes and pick the data with most recent version
- Anti entropy: This is automated read repair where each node communicates with each other.
Quorum guarantees the smooth functioning of leaderless replication.
w + r > n
w = write nodes r = read nodes n = total nodes
What if datacenter failure happens and application cannot reach a quorum. The option is to accept the writes and transfer to the original n home nodes once they are back. This is called sloppy quorum and transfer strategy is hinted handoff. Or, with strict guarantee, we can return an error.