


This article discusses about the various problems with distributed systems - networks,clocks and timing issues and how to reason about the system state after these failures.
Networks
In distributed system parts of the system could fail. These partial failures causes the non determinism as we cant predict what operations will fail. These two together make distributed systems hard to work with and reason about
We heavily focus on Shared-nothing distributed systems. It has become the defacto for building internet services due to below factors.
- It requires no special hardware
- Can use cloud computing services
- High reliability through redundancy
The link between these systems is the unreliable networks which we will discuss below. Internet is an asynchronous(packet switched) network unlike telephone. It is not possible to predict the traffic requirements in internet. There are no guarantees about delays or reliability of the network. Network congestion, queueing, and unbounded delays will happen.
The first step is detecting faults in network.
- If communicating process crashed, OS typically closes TCP connections by sending FIN or RST
- Atlernatively, node can intimate other nodes about failure(as in Hbase)
- But typically,no response indicates that node is down.
This can be detecting by periodically sending requests and waiting for response. But how long should we wait is a difficult problem. Node may be still active but respond a bit delayed. The delay could be due to heavy CPU load at receiver or TCP flow control from sender.
In these cases, systems can continually measure response times and their variability (jitter). Use this information to adjust timeouts according to the observed response time distribution.
Clocks
Time is a tricky business in distributed systems. We will first look at clocks which measure or rather display time.
Time of Day - Well known to humans . Returns current day and time according to some calendar. These are usually kept in sync using Network Time Protocol (NTP) server. These synchronizations might sometimes feel like time is jumping ahead and back. if local node is ahead of NTP server, it will be brought back and vice versa.
Monotonic - Simple example is a counter incrementing at set duration. For example System.nanoTime in java. These are ever increasing and absolute value of it makes no sense. Rather it is used to identify elapsed duration by checking at various time. The difference can be used to identify timeouts of a node. NTP adjusts the frequency at which the monotonic clock moves forward known as slewing the clock. NTP does this if it detects that the computer’s local quartz is moving faster or slower than the NTP server.
NTP based synchronization is very tricky and generally relying on it in distributed systems is very troublesome. Logical clocks are an alternative to physical clocks for ordering events in distributed systems.
We have looked so far at the unreliable nature of distributed systems. How do we go about in this difficult environment ?
Truth is what Majority Says - Concept of Quorum. Node is alive/leader if majority of nodes say so. But still the node can consider itself a leader and tried to boss around (Write to storage etc.)
We can address this by the concept of fencing. Resource is protected by a fence which accepts the request only if fencing token is greater than the last request.
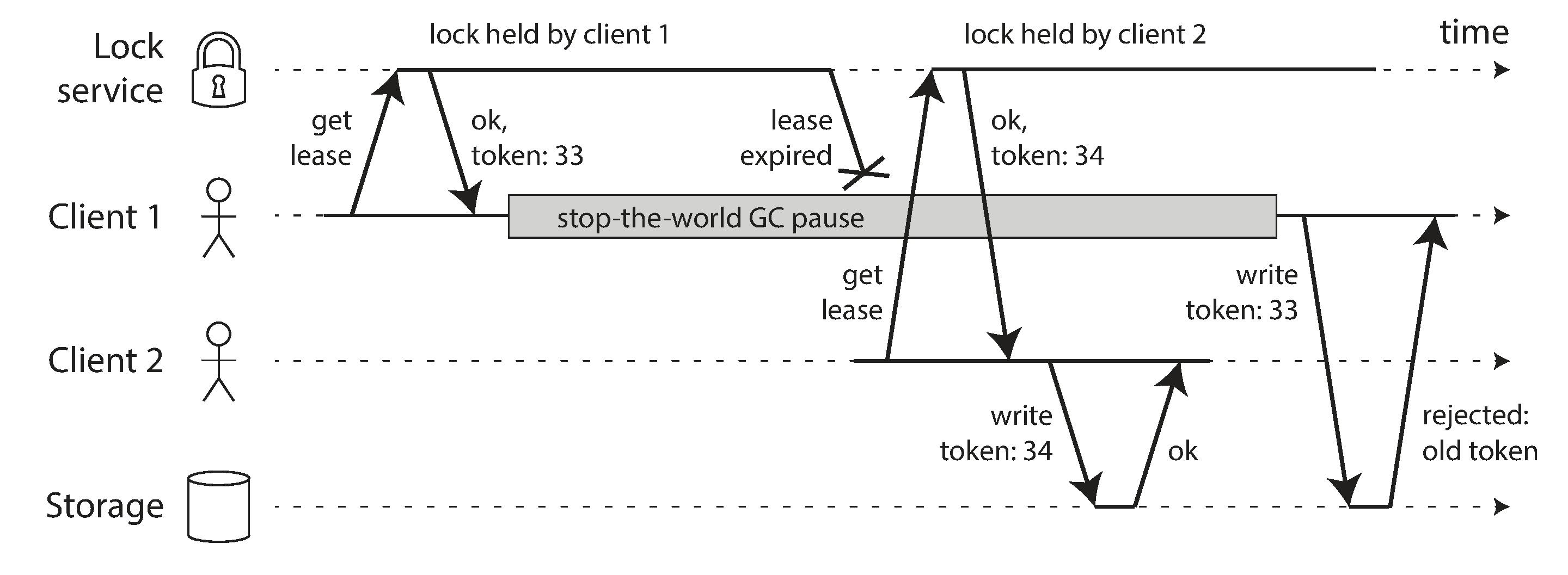 Image from Data Intensive Distributed Applications
Image from Data Intensive Distributed Applications
System Model
Algorithms should have less dependence on hardware details and software configuration. System model is an abstraction of the algorithm's assumption over the potential faults of systems.
With regard to timing assumptions, three system models are in common use:
- Synchronous model : Assumes network delay,process pauses and clock error will be within a fixed upper bound. Not realistic for distributed systems
- Partially synchronous model : Like synchronous but sometimes exceeds the upper bound. Realistic model of many systems today
- Asynchronous model : No Assumptions about clock but very restrictive programming model
The System models for handling node failures are
- Crash-stop faults : A node once failed never comes back online.
- Crash-recovery faults : Node comes back online after sometime but will lose its state.
- Byzantine (arbitrary) faults : Node can do anything even maliciously advertise wrong state.
For modeling real systems, partially synchronous model with crash-recovery faults is generally the most useful model. But how do distributed algorithms cope with that model?. The following properties define the correctness of an algorithm
Safety
Simply put nothing bad happens to the system. We can look at this with example. If we are generating fencing tokens for a lock , we may require the algorithm to have the following properties:
- Uniqueness : No two requests for a fencing token return the same value.
- Monotonic sequence: If request x returned token tx, and request y returned token ty, and x completed before y began, then tx < ty.
Liveness
Bad things could have happened but the system becomes good eventually. An example property would be
- Availability : A node that requests a fencing token and does not crash eventually receives a response.
This chapter has been all about problems with distributed systems. We will move onto handling them in coming chapters.