AWS Read Replicas vs Data Lake(house) for OLAP


The post started with a colleague of mine asking a question
Why we are doing ETL to S3 when we can query from source database?
This question triggered thoughts and we had a discussion. I thought of penning down the summarized discussion and also hear from the world.
The diagram below from AWS represents the usage of read replica. Primary instance serves as the transactional workhorse and Read replica serves analytical workloads. AWS behind the scenes takes care of replicating and ensuring instances are in sync. This does seem a good choice for OLAP workloads.
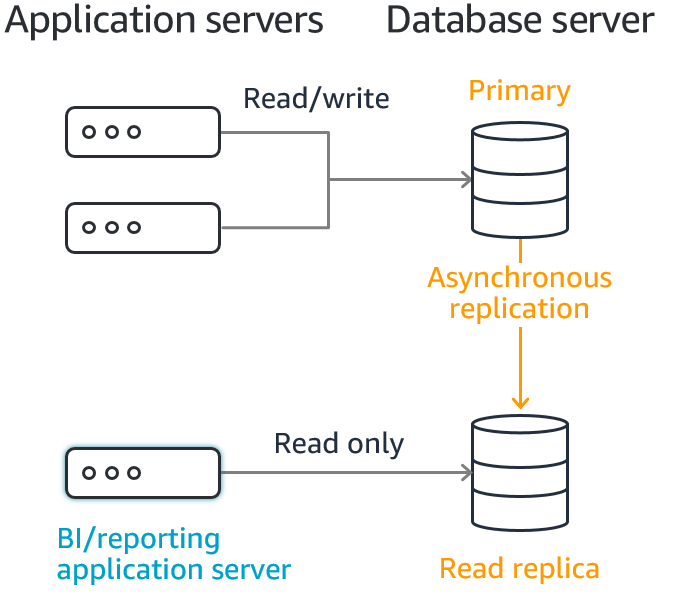 [From AWS]
[From AWS]
Federated query of AWS Athena can help in combining mutiple read replicas. This works for proof of concepts and quick reporting needs.
As we discussed, we identified three reasons where this may not be adequate
Schema Changes
Read replica is a copy of the primary database. Breaking schema changes in database affects the analytical plane as well. This leads to very tight coupling between operational and analytical planes.
A data lake mitigates this problem by supporting schema evolution and service level contracts. Let us consider a customer table with below columns to understand this.
- First Name
- Title
- Last Name
- Address Line 1
- Address Line 2
- City
- ...
This table is used to generate customers by city Report. Now the application needs to evolve for supporting many addresses.
Customer Table
- First Name
- Title
- Last Name
- ...
Address Table
- Address Line 1
- Address Line 2
- City
- CustomerId
- Primary (Yes/No)
Now the report needs to change to include only primary address. Data lake consumes the data from the Customer service which returns primary address of customer. This is stored in denormalized form in data lake storage.
Evolution
The other feature which we would miss is the evolution of a data point. For example, imagine a customer registering for a particular website. Customer has a empty profile at the start. But as time progresses, customer is updating parts of a profile. The transactional system maintains the latest state of customer profile to support UI performance.
Each customer action is an immutable event and represents the profile at that time. Capturing these as events opens up a lot of time series analysis. This helps to gauge and recommend the beneficial aspects of the person's profile.
With Read replicas we would miss out on evolutionary analysis. Transactional databases maintain current state which is a sensible option for performance.
Historic Data
The other major factor is volume of data stored in transactional systems. We start with a low volume of data. But databases tend to grow in size with time which actually represents the success of product in a way.
Maintaining years worth of data in transactional system for analytical operations will slow down the database. Hence transferring to a data lake optimized storage is the right choice for analytical operations
Lets hear from you. What is your thoughts on Read replica vs Lakehouse