
Evolution of data platform - Part 2
Part 2: Performance, Catalog and Access Control


This is part 2 of the series Evolution of data platform. I would recommend reading part 1 before this post
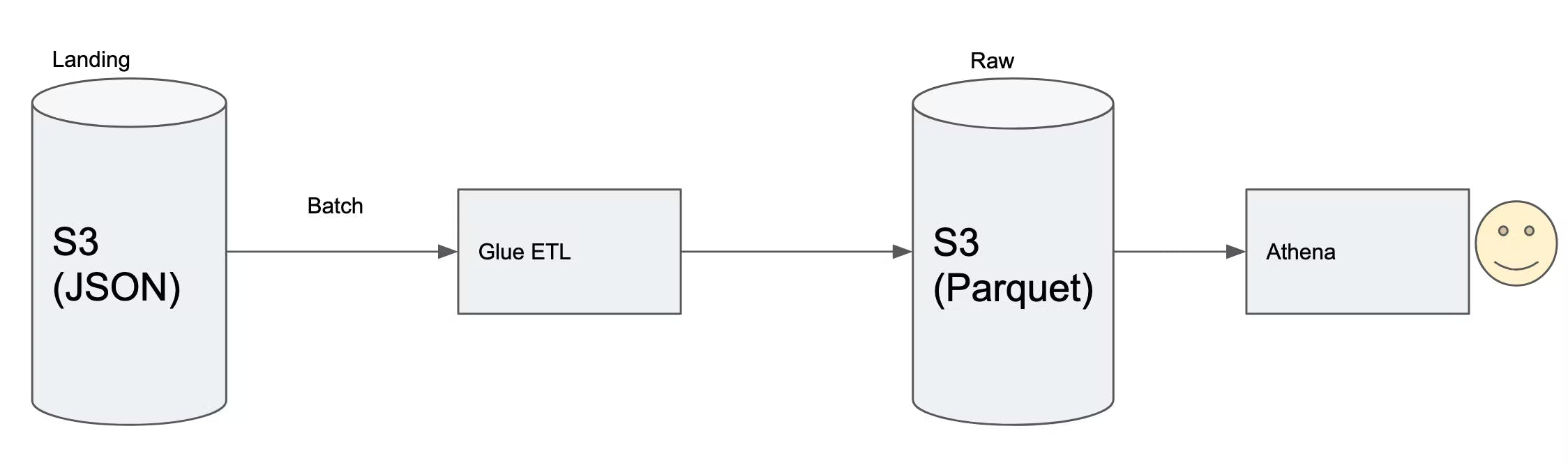
Performance is a long game
Ajar and team were basking in the success of this architecture. After few weeks, the queries were again facing performance issues. Kriti and Kumar already found the reason for it. There was a daily batch which was generating the parquet file under the partition based on access pattern. This partition is a data element very specific to the business. But there was huge number of small files one for each day under the partitioned folder. The day based partitioning would have resulted in the same small file as daily volume was only few Megabytes
So Ajar and team looked at various file formats and databases to understand how this problem was generally solved. Ajar found a reference from Designing Data Intensive Applications by Martin Klepmann. (Refer summary from here). The answer was compaction of these small files.
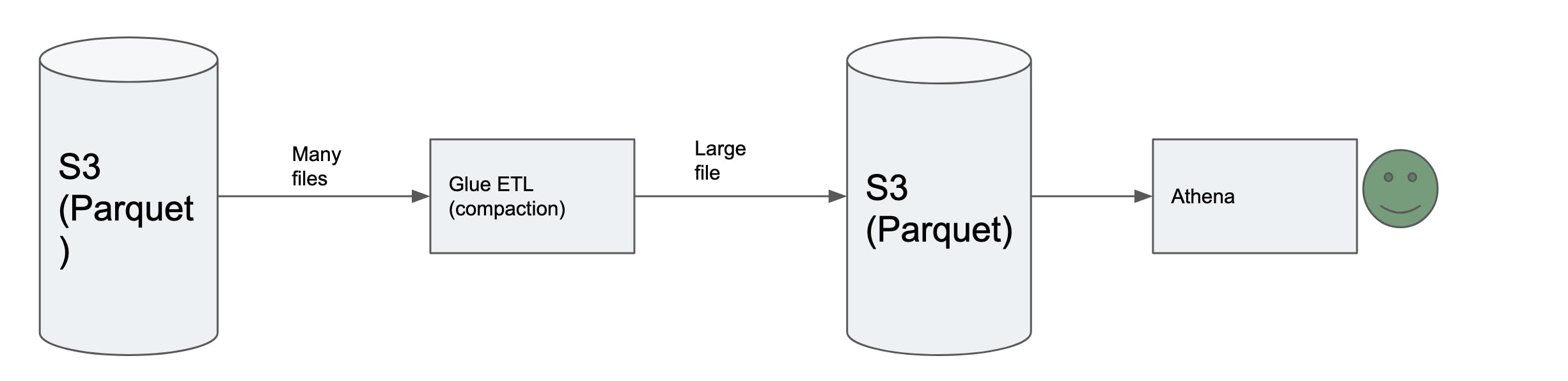
A new batch job was introduced at end of the day to compact these small parquet files into a bigger parquet file(128 MB in size). Once a file crosses 128MB in size, rest of the files are grouped to form the next file. This job operated on per partition basis. This ensured a good performance of queries on ongoing basis.
Do we require all of this engineering complexity and maintenance ?
Friendly File formats
In this approach, there is a lot of handcrafting with the compaction job at file level. Consider the problem of correcting a record in data lake or implementing RTBF(Right to be Forgotten) for a customer. This would entail the following steps
- Find the parquet file containing the records
- Load the entire file and change/delete the required records
- Write the new file back
- Ensure no other job modifies the file during this time
Should the Data Engineers focus on all of this heavy lifting ? This is in addition to all the business related pipelines which data team is responsible for building.
To summarize, the problems are
- Modify few records by key lookup efficiently
- Have a good consistent file size for efficient query performance
- Reduce overall maintenance effort
Let us see few alternatives to the parquet file format which addresses these problems
| Area | Delta Lake | Apache Hudi | Apache Iceberg |
| Description | Storage format from Databricks supporting lakehouse architecture | build streaming data lakes with incremental data pipelines | high-performance format for huge analytic tables |
| Where to use | Well sits within spark ecosystem Provides z Index, vacuum and schema validation capabilities | Provides two types of capabilities Merge on Read Copy on Write (similar to our compaction efforts) | Good choice for handling reads and listing huge number of files |
| Why we did not use | We had mix of python shell jobs and spark jobs. Delta works within spark ecosystem only | Evolving during the project start Currently Good Integration wth EMR | Very limited support in AWS Recently introduced integration with Athena |
These file formats ensure development team focus on business concerns with reduced maintenance effort. Ajar would definitely pick one of these formats for projects beginning today.
How do we get more people to use the data ?
Catalog and Access
Team had grown to 2 developer pairs with a dedicated Quality Analyst and Business Analyst. So far the folks in team had been wearing many hats but now focused on specific areas. The success of the team also meant that there were growing consumers for this data lake. This also meant that consumers need an efficient way to access the data. We already saw that Athena is being used to access this data but Athena is just query engine. It needs a catalog to understand the information stored in data lake.
Ajar and team used the native AWS offering of Glue catalog. Glue supports both push based and pull based mechanism for catalog. The team used both approaches for populating the catalog.
Pull Based
This depends on glue crawlers. Crawlers scan through specified S3 folders and generate the table structure based on the parquet file metadata. It auto creates the partitions based on the folders in S3. Team mainly used it for click stream data as the data dimensions(secondary attributes) varied across each event. This allowed the team to flexibly capture events without restricting the schema.
- ✅ Useful for sources with dynamic schema (Auto identify instead of data team intervention)
- ✅ Reduces effort as partitions are created automatically
- ❗ Corrupt data would create unnecessary partitions and need to be restored with care.
- ❗ Schema mismatch can sometimes occur as schema is inferred from file.
- ❗ Crawler runs on a schedule and data will not be visible in Athena, till the crawler has added the partitions to the catalog. Crawler schedule determines the freshness of your data on top of the ingestion schedule.
- ❗ It is slightly expensive service.
Team scheduled crawler every week to detect schema changes and add new partitions.
Push Based
In this mechanism, the schema is defined upfront by running DDL scripts via Athena Query engine. This is suitable for fixed schema sources and evolution needs manual intervention
- ✅ Greater control of schema.
- ✅ Bad data may make table non usable but can isolate the files and correct the problem quickly.
- ✅ Team ran add partition command as part of the ingestion job to keep partitions upto date.(Fresh data as soon as possible)
- ❗ To add partitions, needs manual effort.
- ❗ Would need manual intervention many times for widely changing schema
Glue catalog suited the team purpose in their initial journey. The initial consumers were Business Analysts and developers who were comfortable with getting their hands dirty. But the team found few shortcomings as part of their usage in the wild
- It did not have lineage for transformed views. Much needed for data consumers
- Data Discoverability was not great in Glue. Using another service with combination of glue is extra effort(eg: Amazon Kendra or elastic search)
- Out of the box statistics needs to be improved
- Common queries can help consumers a lot . Ability to provide detailed description at table and column level is necessary
Team is currently looking at something like DataHub for robust capabilities
The team was so far dealing with non PII(Personally Identifiable Information) data. But, a particular source system had personal data. At first, the team debated should it really bring PII data into the platform. The consumer usecase needed a personalization service to send mails based on user's activity in the platform. Hence team decided to bring in the PII data.
This presented a problem of restricting access to consumers. PII data should be accessible to email service but not to other consumers. Krithi did research on this problem and suggested AWS Lake formation
Lakeformation works in conjuction with Glue Catalog and gives the flexibility to grant access at column level to IAM roles.
AWS has been doing some serious improvements to lakeformation. This article presents how lakeformation brings ACID compliance and row level security to data lake. Lakeformation governed tables is also a good alternative to the lake formats we discussed above.
How do we choose an ETL platform ?
Glue vs EMR
Ajar and team ran most of the workloads in AWS Glue. There was a spirited discussion of using AWS offering of Elastic map reduce. The team decided on AWS Glue against EMR for the following reasons
- Team had few small workloads which were predominantly python shell jobs. Porting them to Spark was unnecessary.
- Having always on EMR cluster meant a fixed cost but it was expensive for few batch workloads(not 100s of jobs). Most of the jobs ran in 5-6 hour interval.
- Provisioning an on demand EMR cluster meant we had to account the cluster provisioning time. EMR cluster also meant doing appropriate sizing and scaling of instances(Can be mitigated by using EKS and EMR). We were only running spark workloads and heavily using other AWS services. Though EMR had good configurability for Big data stack, Glue was satisfactory for team’s use case.
- Glue was serverless and it also had an inbuilt scheduler. Team did not have nested/complex workflows. All this meant Glue was quite adequate for the use case.
Glue incurs a slightly higher cost than on demand EMR cluster in terms of cpu per hour. But the ease of setup outweigh the cost. EMR is preferrable when volume is high and usecase involves variety of tools in Big data stack.
Takeaways
- Choose appropriate file format for the use case. Recommend use of lake file systems like Delta lake, Hudi or iceberg.
- Data catalog is a key component in a data platform. This will be your gateway for Data Activation across the enterprise.
- Role Based Access Control will definitely creep in your data platform with or without PII data. Lake formation is a robust offering in that regard. Apache ranger has better support if you are using AWS EMR.
- AWS Glue provides a scheduler,catalog and serverless runtime for ETL. Definite recommendation unless your usecase outgrows Glue